print を貼り続けるだけでは、いつか限界がくる
エラーが出たとき、最初にやることは何でしょうか。多くの人は print(変数名) をコードのあちこちに差し込み、動作を確認しながら原因を探っていくと思います。この方法は手軽で、入門段階では十分に機能します。しかし規模の大きなコードや複雑な処理の流れの中でバグを追うとき、printデバッグは急速に限界を露呈します。
どこにprintを入れたか分からなくなる。修正後にprintを消し忘れて本番に出てしまう。ループの中で大量の出力が流れて肝心な値が見えなくなる。こうした経験を繰り返しているなら、デバッグの道具箱を見直す時期が来ています。
デバッグとは「バグを偶然見つける作業」ではなく、「仮説を立てて検証する技術」です。この記事では、Pythonを例に取りながら、エラーメッセージの正しい読み方から始めて、デバッガの使い方、ログの活用、そして効率よくバグを潰す思考法まで、体系的に解説します。
エラーメッセージを正確に読む
デバッグの第一歩はエラーメッセージをきちんと読むことです。当たり前のように聞こえますが、多くの初心者は最後の1行(エラーの種類と内容)だけを見て、その上のトレースバック全体を飛ばしてしまいます。
Traceback (most recent call last):
File "app.py", line 52, in handle_request
result = calculate_total(cart)
File "billing.py", line 18, in calculate_total
return sum(item["price"] for item in items) * (1 + tax_rate)
File "billing.py", line 18, in <genexpr>
return sum(item["price"] for item in items) * (1 + tax_rate)
KeyError: 'price'
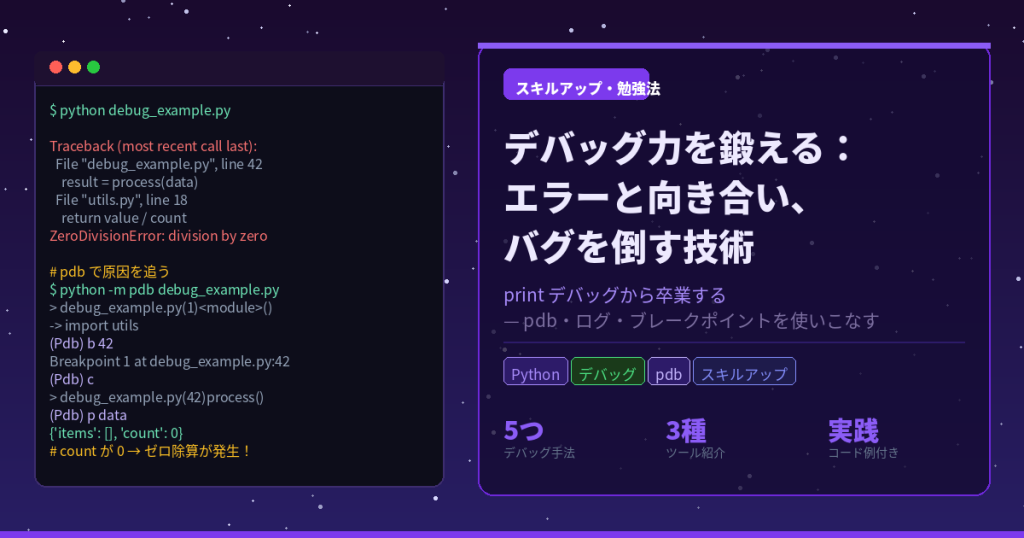
このトレースバックが語っていることを順番に読み解いてみましょう。まず、エラーは app.py の52行目から始まった呼び出しが連鎖した末に発生しています。次に、実際にエラーが起きたのは billing.py の18行目です。最後の行 KeyError: 'price' が教えているのは「price というキーが辞書に存在しなかった」ということです。
つまり確認すべきは「cart に渡されたデータの中に、price キーを持たない要素が混入している」という可能性です。printデバッグなら print(cart) と書いてリストの中身を見に行くところですが、ここで次に紹介するデバッガを使うと、その場でデータ構造を自由に検査できます。
pdb:Pythonの標準デバッガを使いこなす
pdb はPythonに標準で付属しているデバッガです。インストール不要で使え、コードの任意の場所で実行を一時停止して変数の中身を調べたり、1行ずつ実行を追ったりすることができます。
ブレークポイントの設置
Python 3.7以降であれば、一時停止したい行の直前に breakpoint() と書くだけで起動します。
def calculate_total(items, tax_rate):
breakpoint() # ← ここで実行が止まる
return sum(item["price"] for item in items) * (1 + tax_rate)
スクリプトを実行すると、その行に到達した時点でpdbのプロンプト (Pdb) が表示され、対話モードに入ります。
よく使うpdbコマンド
| コマンド | 省略形 | 意味 |
|---|---|---|
next | n | 現在の行を実行して次の行へ進む |
step | s | 関数の中へ入って1行ずつ追う |
continue | c | 次のブレークポイントまで実行を続ける |
print 変数名 | p 変数名 | 変数の値を表示する |
list | l | 現在位置周辺のコードを表示する |
where | w | コールスタック(呼び出し履歴)を表示する |
quit | q | デバッガを終了する |
先ほどの KeyError を例に使ってみましょう。ブレークポイントで止まったら、まず p items と入力してリストの中身を確認します。すると [{'name': '本', 'price': 1200}, {'name': 'メモ帳'}] のように、price キーを持たない要素がひとつ混じっていることが一目で分かります。これがprintデバッグとの最大の違いです。コードを書き換えることなく、必要な変数をその場で何度でも調べられます。
VS Codeのビジュアルデバッガ
コマンドライン操作が苦手な場合は、VS CodeのPython拡張が提供するGUIデバッガが強力な選択肢です。コードの行番号の左側をクリックするだけでブレークポイントを設定でき、変数の一覧・コールスタック・ウォッチ式がパネルに並びます。操作の流れはpdbと同じですが、視覚的に把握できるため直感的に扱えます。
ログを戦略的に使う
本番環境ではデバッガを使えません。そのため、実務では logging モジュールによるログ出力がデバッグの主要手段になります。printとloggingの最大の違いは「レベル」の概念があることです。
import logging
# 基本設定(実行レベルとフォーマットを指定)
logging.basicConfig(
level=logging.DEBUG,
format="%(asctime)s [%(levelname)s] %(name)s - %(message)s"
)
logger = logging.getLogger(__name__)
def calculate_total(items, tax_rate):
logger.debug("calculate_total called: items=%s, tax_rate=%s", items, tax_rate)
total = sum(item["price"] for item in items)
logger.info("Subtotal: %s", total)
return total * (1 + tax_rate)
ログレベルは重要度に応じて5段階あります。
| レベル | 用途 |
|---|---|
DEBUG | 開発時の詳細な内部状態(本番では通常オフ) |
INFO | 正常な処理の進行状況 |
WARNING | 問題ではないが注意が必要な状態 |
ERROR | エラーが発生したが処理は継続できる |
CRITICAL | システムが停止する可能性がある深刻なエラー |
開発環境では DEBUG 以上のすべてのログを出力し、本番環境では WARNING 以上のみを記録する、というように環境変数で切り替える運用が一般的です。この設計があれば、本番でエラーが起きたときにもログから原因を追跡できます。
バグを効率よく潰す思考法
ツールの使い方を覚えるだけでは、デバッグは速くなりません。大切なのは「どこを見るか」という仮説を立てる力です。
二分探索で原因を絞り込む
バグの原因箇所が分からないとき、コード全体を一行ずつ追うのは非効率です。まず処理の中間地点でブレークポイントを設定し、「ここまでは正常か」を確認します。正常であれば後半に、異常であれば前半に原因があります。この繰り返しで原因を半分ずつ絞り込むアプローチは「二分探索デバッグ」と呼ばれ、大きなコードベースでも効率よく対応できます。
再現手順を最小化する
バグが見つかったら、最初にやることは「最小の再現コードを作ること」です。本番データで発生するバグを本番環境でしか確認できない状態では、調査に時間がかかります。原因に関係のないコードを削ぎ落として、10行程度で問題を再現できるサンプルを作れれば、原因の特定は一気に近づきます。
「直す」前に「理解する」
バグを見つけたとき、すぐに修正コードを書き始めたくなる気持ちは分かります。しかし「なぜそのバグが起きたか」を完全に理解する前に修正すると、別の問題を生み出すことが少なくありません。まず「このバグはどのような条件のときに発生するか」を言語化してみましょう。言語化できれば、修正方針が自然に見えてきます。
まとめ
デバッグは「運よく見つかれば儲けもの」な作業ではなく、再現・仮説・検証というサイクルで進める技術です。printデバッグは入口として有効ですが、pdb やIDEのデバッガ、logging モジュールを組み合わせることで、バグを追う速度と精度は格段に上がります。
エラーメッセージを丁寧に読み、ブレークポイントで止めてデータを検証し、ログで状態を記録する。この3つを習慣化するだけで、「バグに振り回される時間」は大きく減っていきます。デバッグが上手いエンジニアは、焦らず落ち着いてコードと対話できるエンジニアでもあります。